As I mentioned last week, I’ve recently been doing a bunch of development and other work with the iPad Pro. This has generally been going very well – the only thing I have to go back to my Mac for, at the moment, is QuickBooks. (And yes, I know there is an online version of QuickBooks – however, there is one thing in it that didn’t work well for me last time I tried it, so for now I’m still using the desktop version.)
Part of what I do on a day-to-day basis is web development, using Ruby and Rails. To do this on the Mac I use Sublime Text, and a couple of terminal windows to accomplish what I need. If we break this down a bit, this is what’s needed for development:
- An editor for editing source files
- A terminal window of some sort for running specs, deploying code, etc
- A browser for testing changes
There isn’t any requirement that that editor needs to be editing files on your local machine, nor that the terminal window needs to be a session on the local machine, nor that the browser needs to point to the local machine. Which forms the basis for a reasonable iPad-based workflow for development.
I’ve been doing this using a combination of a development VPS running Linux, and a few tools on the iPad Pro. The main tool I’ve been using is Coda, which combines an editor, SSH client, and FTP client together in one app. In my experience, Coda is sometimes a bit buggy (random crashes, sometimes freezes for a few seconds at a time, sometimes line numbers go haywire), but for the most part it’s quite polished, and definitely worth using.
And Coda has one feature that really ties everything together – it can edit remote files (on my development VPS) directly, without having to explicitly transfer them. Don’t worry – I’m not editing live files on a production server; rather, I’m editing files live on a development VPS, and connecting to that dev machine using Coda.
When I want to make some changes to the site, I simply:
- Start up a new VPS from an image I’ve created
- Connect to that image from Coda
- Make code changes with the Coda editor
- Test changes with a browser pointing to the VPS
- Run specs, commit changes, etc. using Coda’s SSH client
All in all, this works just as well as making code changes from the desktop – the only real difference is using the Coda editor rather than Sublime Text.
Optimizing the VPS workflow for Linode
I could just create the development VPS and leave it running all the time, waiting for me to connect and use it. However, it’s almost as easy to start and stop the VPS as necessary, and we’ll save a few bucks doing it this way. Plus we can have some more fun, with Pythonista, which was recently updated for the iPad Pro!
The steps and scripts below are for Linode (shameless referral link), but you can do this anywhere you like. Here are similar scripts for AWS/EC2. But for Linode, this is what we need to do:
- Create a development server VPS. Install whatever software you need (e.g. Ruby, etc.), clone your source code into a folder, and basically get everything up and running.
- Create a saved image of that VPS, using the Linode Manager tools.
- Assuming you have the image saved, you can now delete the original VPS.
You now have a saved image, that you can create a new VPS from any time you like. But that will be a lot of tapping around on the Linode Manager to do so…so instead, we can use a script (which uses the Linode API) to automate this, and run this script in Pythonista.
It turns out this script has to do quite a few things; creating a new node from an image in the Linode Manager hides some of these steps from you (like setting up a configuration profile), but we must do them all manually when using the API.
To get set up, first copy the api.py file from the linode-python GitHub repository to Pythonista. You can copy down the entire repo if you want, but the api.py is the part we need. Then, you can use this script in Pythonista to create a new node:
This script assumes it’s in the same directory as api.py, and further assumes the following:
- You have an manually-created image saved, and that image is called “dev image”
- You want the new node to be called “dev01”, and be saved in a group called “Dev”
- You want your new node to be in the Dallas data center, and you want it to be on the Linode 1024 plan; it will be set up with a 22GB main volume, and a 256MB swap volume, with the latest 64-bit kernel.
You can change any of the above assumptions by editing the code on lines 20-26.
The script will create a new VPS, and will copy the public IP of the new node to the clipboard. From there, you can open Coda, create or edit a site configuration there, and paste in the new IP. In my experience, by the time you open Coda and paste in the new IPs, the VPS will be booted and ready to connect.
To make things a bit more automated, I run the script from a workflow in the Workflow app; here is a screenshot of the workflow I use:
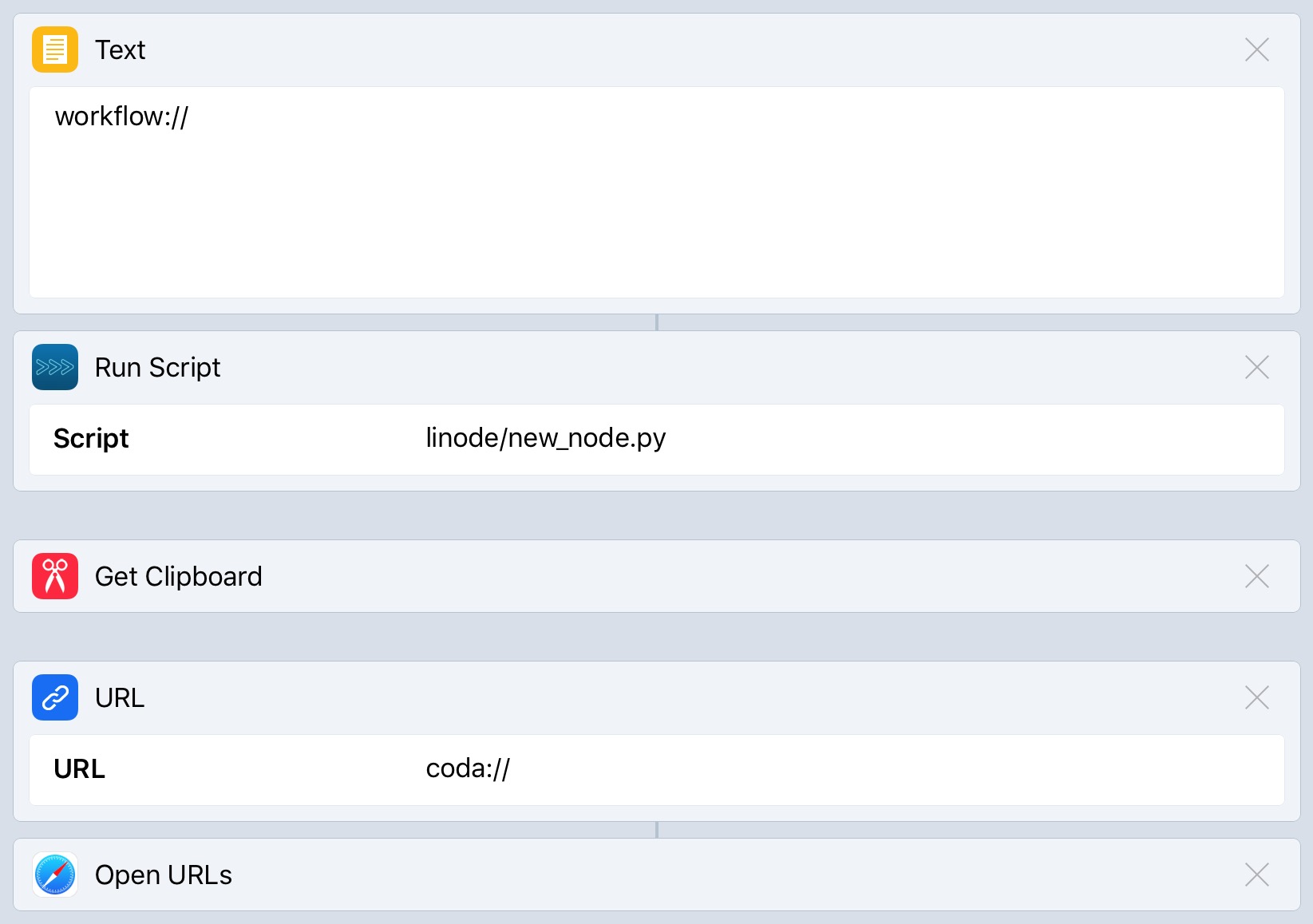
It’s quite simple – it just runs the Pythonista script, sending “workflow://” as the return URL, and then opens Coda, with the new IP address on the clipboard ready to paste into your site configuration. I add a shortcut to the workflow to my home screen, and I can spin up a new node with literally one tap. But if you want to, you could do the equivalent without using Workflow at all in this case.
We can also delete the node when we’re done, using another script; be careful with this one, and make sure you completely understand what it’s doing before you run it – if it finds a node called dev01 in the Dev group, it will delete it without confirmation:
Using these scripts and the apps I’ve mentioned, I’ve found development on the iPad Pro (with a keyboard) can be quite similar to the equivalent on a desktop.